


LZ77 编码简介
- LZ 编码由以色列研究者 Jacob Ziv 和 Abraham Lempel 提出,是无损压缩的核心思想。LZ 是一个系列的算法,而其中最基本的就是两人在 1977年所发表的论文《A Universal Algorithm for Sequential Compression》 中提出的 LZ77 算法。
- LZ77 压缩是一种基于字典及滑动窗口的无损压缩技术,广泛应用于通信传输。
- LZ77 算法不同于 Huffman 编码等基于统计的数据压缩编码,需要得到先验知识——信源的字符频率,然后进行压缩。
- LZ77的核心思想:利用数据的重复结构信息来进行数据压缩。
LZ77 的基本原理
- LZ77 以经常出现的字母组合(或较长的字符串)构建字典中的数据项,并且使用较短的数字(或符号)编码来代替比较复杂的数据项。数据压缩时,将从待压缩数据中读入的源数据与字典中的数据项进行匹配,从中检索出相应的代码并输出。从而实现数据的压缩
- 在 LZ77 方法中,词典就是先前已编码序列的一部分。编码器通过一个滑动窗口来查看输入序列,如下图所示。
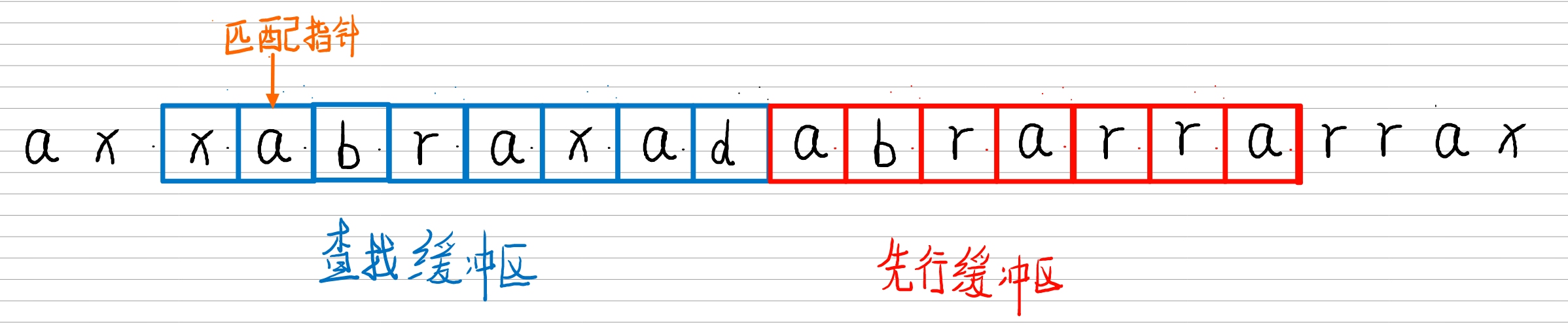
- 这个滑动窗口包括两个部分:查找缓冲区(Search Buffer) 和 先行缓冲区(Look Ahead Buffer)
- 查找缓冲区:包含了最近已编码序列的一部分
- 先行缓冲区:包含待编码序列的下一部分
这里查找缓冲区包含了 8 个符号,先行缓冲区包含 7 个符号。但在实际情况中,缓冲区要大很多。
三元组参数解释:
- ① 匹配指针 先在 查找缓冲区 中找到移动指针,知道找到与先行缓冲区第一个字符a相匹配字符a。此时该指针与先行缓冲区的距离称为 偏移量(off) 。这里的 偏移量off 就是7。
- ② 编码器之后查看指针位置之后的符号,查看其是否与先行缓冲区的符号相匹配。从第一个符号(匹配指针以开始所指向的位置)开始,与先行缓冲区的符号匹配,匹配到的连续符号的长度称为 匹配长度(len)。例如这里,从匹配指针所指的位置开始的符号串 abra 与 先行缓冲区中的符号串 abra 相匹配,下一位查找缓冲区的 x 与 先行缓冲区 a 不匹配,所以这里的 匹配长度len 是 4.。
- ③ 编码器在查找缓冲区中搜素最长匹配串。找到最长的匹配串后,编码器即可用三元组
LZ77 算法
-
LZ77 算法执行流程如下:
步骤 1:从输入的待压缩数据的起始位置,读取未编码的源数据,从滑动窗口的字典数据项中查找最长的匹配字符串。若结果为 T,则执行步骤 2,若结果为 F,则执行步骤 3;
步骤 2:输出函数 F(off,len,c)。然后将窗口向后滑动到 len++,继续步骤 1;
步骤 3:输出函数 F(0,0,c),其中 c 为下一个字符。并且窗口向后滑动(len + 1)个字符,执行步骤 1。 -
下面是代码实现:
/* PROG1.C */ /* Simple Hashing LZ77 Sliding Dictionary Compression Program */ /* By Rich Geldreich, Jr. October, 1993 */ /* Originally compiled with QuickC v2.5 in the small model. */ #include#include #include #include /* set this to 1 for a greedy encoder */ #define GREEDY 0 /* ratio vs. speed constant */ /* the larger this constant, the better the compression */ #define MAXCOMPARES 75 /* unused entry flag */ #define NIL 0xFFFF /* bits per symbol- normally 8 for general purpose compression */ #define CHARBITS 8 /* minimum match length & maximum match length */ #define THRESHOLD 2 #define MATCHBITS 4 #define MAXMATCH ((1 << MATCHBITS) + THRESHOLD - 1) /* sliding dictionary size and hash table's size */ /* some combinations of HASHBITS and THRESHOLD values will not work correctly because of the way this program hashes strings */ #define DICTBITS 13 #define HASHBITS 10 #define DICTSIZE (1 << DICTBITS) #define HASHSIZE (1 << HASHBITS) /* # bits to shift after each XOR hash */ /* this constant must be high enough so that only THRESHOLD + 1 characters are in the hash accumulator at one time */ #define SHIFTBITS ((HASHBITS + THRESHOLD) / (THRESHOLD + 1)) /* sector size constants */ #define SECTORBIT 10 #define SECTORLEN (1 << SECTORBIT) #define SECTORAND ((0xFFFF << SECTORBIT) & 0xFFFF) /* dictionary plus MAXMATCH extra chars for string comparisions */ unsigned char dict[DICTSIZE + MAXMATCH]; /* hashtable & link list table */ unsigned int hash[HASHSIZE], nextlink[DICTSIZE]; /* misc. global variables */ unsigned int matchlength, matchpos, bitbuf, bitsin, masks[17] = {0,1,3,7,15,31,63,127,255,511,1023,2047,4095,8191,16383,32767,65535}; FILE *infile, *outfile; /* writes multiple bit codes to the output stream */ void SendBits(unsigned int bits, unsigned int numbits) { bitbuf |= (bits << bitsin); bitsin += numbits; if (bitsin > 16) /* special case when # bits in buffer exceeds 16 */ { if (putc(bitbuf & 0xFF, outfile) == EOF) { printf("nerror writing to output file"); exit(EXIT_FAILURE); } bitbuf = bits >> (8 - (bitsin - numbits)); bitsin -= 8; } while (bitsin >= 8) { if (putc(bitbuf & 0xFF, outfile) == EOF) { printf("nerror writing to output file"); exit(EXIT_FAILURE); } bitbuf >>= 8; bitsin -= 8; } } /* reads multiple bit codes from the input stream */ unsigned int ReadBits(unsigned int numbits) { register unsigned int i; i = bitbuf >> (8 - bitsin); while (numbits > bitsin) { if ((bitbuf = getc(infile)) == EOF) { printf("nerror reading from input file"); exit(EXIT_FAILURE); } i |= (bitbuf << bitsin); bitsin += 8; } bitsin -= numbits; return (i & masks[numbits]); } /* sends a match to the output stream */ void SendMatch(unsigned int matchlen, unsigned int matchdistance) { SendBits(1, 1); SendBits(matchlen - (THRESHOLD + 1), MATCHBITS); SendBits(matchdistance, DICTBITS); } /* sends one character (or literal) to the output stream */ void SendChar(unsigned int character) { SendBits(0, 1); SendBits(character, CHARBITS); } /* initializes the search structures needed for compression */ void InitEncode(void) { register unsigned int i; for (i = 0; i < HASHSIZE; i++) hash[i] = NIL; nextlink[DICTSIZE] = NIL; } /* loads dictionary with characters from the input stream */ unsigned int LoadDict(unsigned int dictpos) { register unsigned int i, j; if ((i = fread(&dict[dictpos], sizeof (char), SECTORLEN, infile)) == EOF) { printf("nerror reading from input file"); exit(EXIT_FAILURE); } /* since the dictionary is a ring buffer, copy the characters at the very start of the dictionary to the end */ if (dictpos == 0) { for (j = 0; j < MAXMATCH; j++) dict[j + DICTSIZE] = dict[j]; } return i; } /* deletes data from the dictionary search structures */ /* this is only done when the number of bytes to be compressed exceeds the dictionary's size */ void DeleteData(unsigned int dictpos) { register unsigned int i, j; j = dictpos; /* put dictpos in register for more speed */ /* delete all references to the sector being deleted */ for (i = 0; i < DICTSIZE; i++) if ((nextlink[i] & SECTORAND) == j) nextlink[i] = NIL; for (i = 0; i < HASHSIZE; i++) if ((hash[i] & SECTORAND) == j) hash[i] = NIL; } /* hash data just entered into dictionary */ /* XOR hashing is used here, but practically any hash function will work */ void HashData(unsigned int dictpos, unsigned int bytestodo) { register unsigned int i, j, k; if (bytestodo <= THRESHOLD) /* not enough bytes in sector for match? */ for (i = 0; i < bytestodo; i++) nextlink[dictpos + i] = NIL; else { /* matches can't cross sector boundries */ for (i = bytestodo - THRESHOLD; i < bytestodo; i++) nextlink[dictpos + i] = NIL; j = (((unsigned int)dict[dictpos]) << SHIFTBITS) ^ dict[dictpos + 1]; k = dictpos + bytestodo - THRESHOLD; /* calculate end of sector */ for (i = dictpos; i < k; i++) { nextlink[i] = hash[j = (((j << SHIFTBITS) & (HASHSIZE - 1)) ^ dict[i + THRESHOLD])]; hash[j] = i; } } } /* finds match for string at position dictpos */ /* this search code finds the longest AND closest match for the string at dictpos */ void FindMatch(unsigned int dictpos, unsigned int startlen) { register unsigned int i, j, k; unsigned char l; i = dictpos; matchlength = startlen; k = MAXCOMPARES; l = dict[dictpos + matchlength]; do { if ((i = nextlink[i]) == NIL) return; /* get next string in list */ if (dict[i + matchlength] == l) /* possible larger match? */ { for (j = 0; j < MAXMATCH; j++) /* compare strings */ if (dict[dictpos + j] != dict[i + j]) break; if (j > matchlength) /* found larger match? */ { matchlength = j; matchpos = i; if (matchlength == MAXMATCH) return; /* exit if largest possible match */ l = dict[dictpos + matchlength]; } } } while (--k); /* keep on trying until we run out of chances */ } /* finds dictionary matches for characters in current sector */ void DictSearch(unsigned int dictpos, unsigned int bytestodo) { register unsigned int i, j; #if (GREEDY == 0) unsigned int matchlen1, matchpos1; /* non-greedy search loop (slow) */ i = dictpos; j = bytestodo; while (j) /* loop while there are still characters left to be compressed */ { FindMatch(i, THRESHOLD); if (matchlength > THRESHOLD) { matchlen1 = matchlength; matchpos1 = matchpos; for ( ; ; ) { FindMatch(i + 1, matchlen1); if (matchlength > matchlen1) { matchlen1 = matchlength; matchpos1 = matchpos; SendChar(dict[i++]); j--; } else { if (matchlen1 > j) { matchlen1 = j; if (matchlen1 <= THRESHOLD) { SendChar(dict[i++]); j--; break; } } SendMatch(matchlen1, (i - matchpos1) & (DICTSIZE - 1)); i += matchlen1; j -= matchlen1; break; } } } else { SendChar(dict[i++]); j--; } } #else /* greedy search loop (fast) */ i = dictpos; j = bytestodo; while (j) /* loop while there are still characters left to be compressed */ { FindMatch(i, THRESHOLD); if (matchlength > j) matchlength = j; /* clamp matchlength */ if (matchlength > THRESHOLD) /* valid match? */ { SendMatch(matchlength, (i - matchpos) & (DICTSIZE - 1)); i += matchlength; j -= matchlength; } else { SendChar(dict[i++]); j--; } } #endif } /* main encoder */ void Encode (void) { unsigned int dictpos, deleteflag, sectorlen; unsigned long bytescompressed; InitEncode(); dictpos = deleteflag = 0; bytescompressed = 0; while (1) { /* delete old data from dictionary */ if (deleteflag) DeleteData(dictpos); /* grab more data to compress */ if ((sectorlen = LoadDict(dictpos)) == 0) break; /* hash the data */ HashData(dictpos, sectorlen); /* find dictionary matches */ DictSearch(dictpos, sectorlen); bytescompressed += sectorlen; printf("r%ld", bytescompressed); dictpos += SECTORLEN; /* wrap back to beginning of dictionary when its full */ if (dictpos == DICTSIZE) { dictpos = 0; deleteflag = 1; /* ok to delete now */ } } /* Send EOF flag */ SendMatch(MAXMATCH + 1, 0); /* Flush bit buffer */ if (bitsin) SendBits(0, 8 - bitsin); return; } /* main decoder */ void Decode (void) { register unsigned int i, j, k; unsigned long bytesdecompressed; i = 0; bytesdecompressed = 0; for ( ; ; ) { if (ReadBits(1) == 0) /* character or match? */ { dict[i++] = ReadBits(CHARBITS); if (i == DICTSIZE) { if (fwrite(&dict, sizeof (char), DICTSIZE, outfile) == EOF) { printf("nerror writing to output file"); exit(EXIT_FAILURE); } i = 0; bytesdecompressed += DICTSIZE; printf("r%ld", bytesdecompressed); } } else { /* get match length from input stream */ k = (THRESHOLD + 1) + ReadBits(MATCHBITS); if (k == (MAXMATCH + 1)) /* Check for EOF flag */ { if (fwrite(&dict, sizeof (char), i, outfile) == EOF) { printf("nerror writing to output file"); exit(EXIT_FAILURE); } bytesdecompressed += i; printf("r%ld", bytesdecompressed); return; } /* get match position from input stream */ j = ((i - ReadBits(DICTBITS)) & (DICTSIZE - 1)); if ((i + k) >= DICTSIZE) { do { dict[i++] = dict[j++]; j &= (DICTSIZE - 1); if (i == DICTSIZE) { if (fwrite(&dict, sizeof (char), DICTSIZE, outfile) == EOF) { printf("nerror writing to output file"); exit(EXIT_FAILURE); } i = 0; bytesdecompressed += DICTSIZE; printf("r%ld", bytesdecompressed); } } while (--k); } else { if ((j + k) >= DICTSIZE) { do { dict[i++] = dict[j++]; j &= (DICTSIZE - 1); } while (--k); } else { do { dict[i++] = dict[j++]; } while (--k); } } } } } int main(int argc, char *argv[]) { char *s; if (argc != 4) { printf("n'prog1 e file1 file2' encodes file1 into file2.n" "'prog1 d file2 file1' decodes file2 into file1.n"); return EXIT_FAILURE; } if ((s = argv[1], s[1] || strpbrk(s, "DEde") == NULL) || (s = argv[2], (infile = fopen(s, "rb")) == NULL) || (s = argv[3], (outfile = fopen(s, "wb")) == NULL)) { printf("??? %sn", s); return EXIT_FAILURE; } /* allocate 4k I/O buffers for a little speed */ setvbuf( infile, NULL, _IOFBF, 4096); setvbuf( outfile, NULL, _IOFBF, 4096); if (toupper(*argv[1]) == 'E') { printf("Compressing %s to %sn", argv[2], argv[3]); Encode(); } else { printf("Decompressing %s to %sn", argv[2], argv[3]); Decode(); } fclose(infile); fclose(outfile); return EXIT_SUCCESS; }
参考文献
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END





暂无评论内容